1. Descriptive statistics: two numbers that are as good as a million
In this section, we will learn about descriptive statistics.
The main purpose of descriptive statistics to summarise a group.
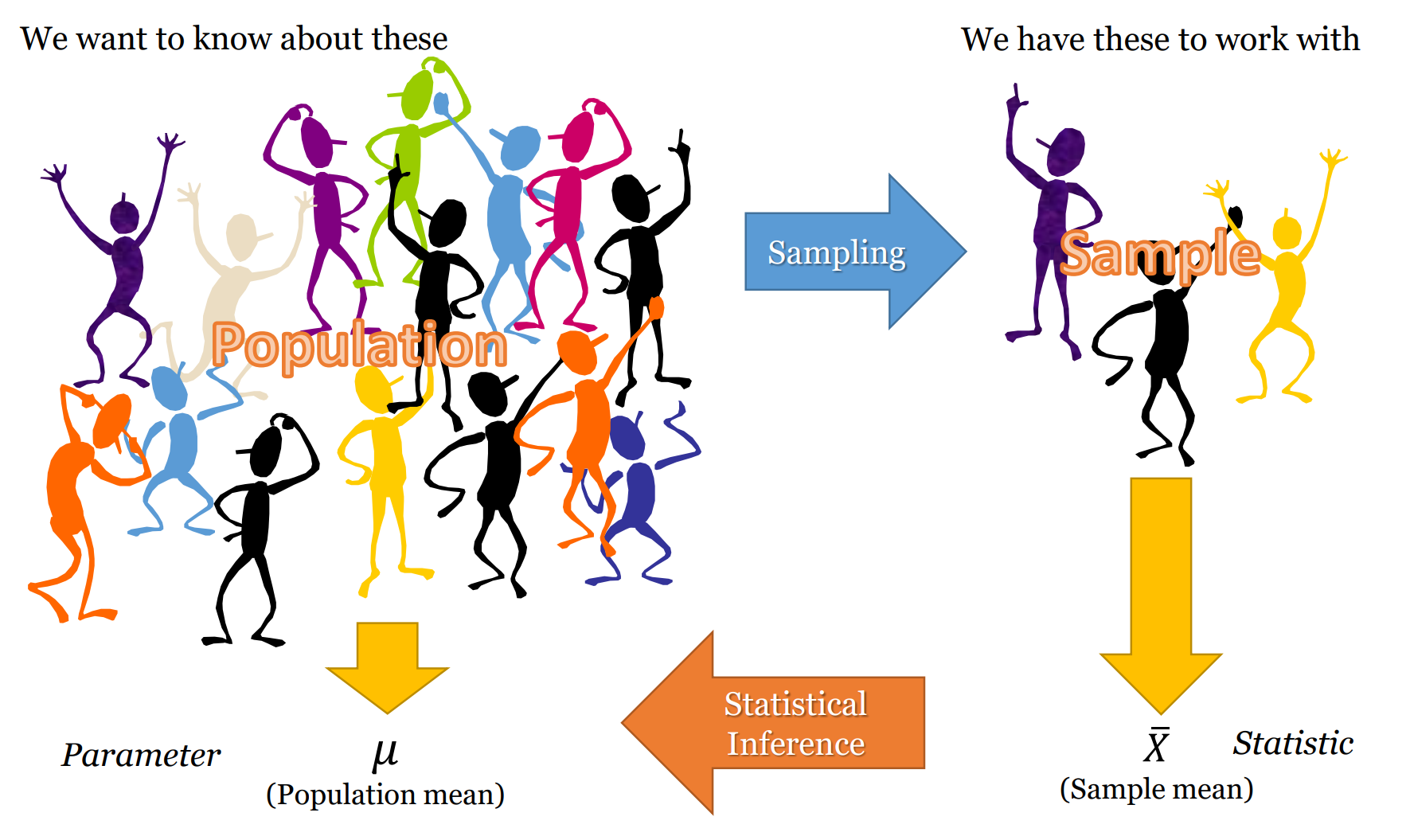
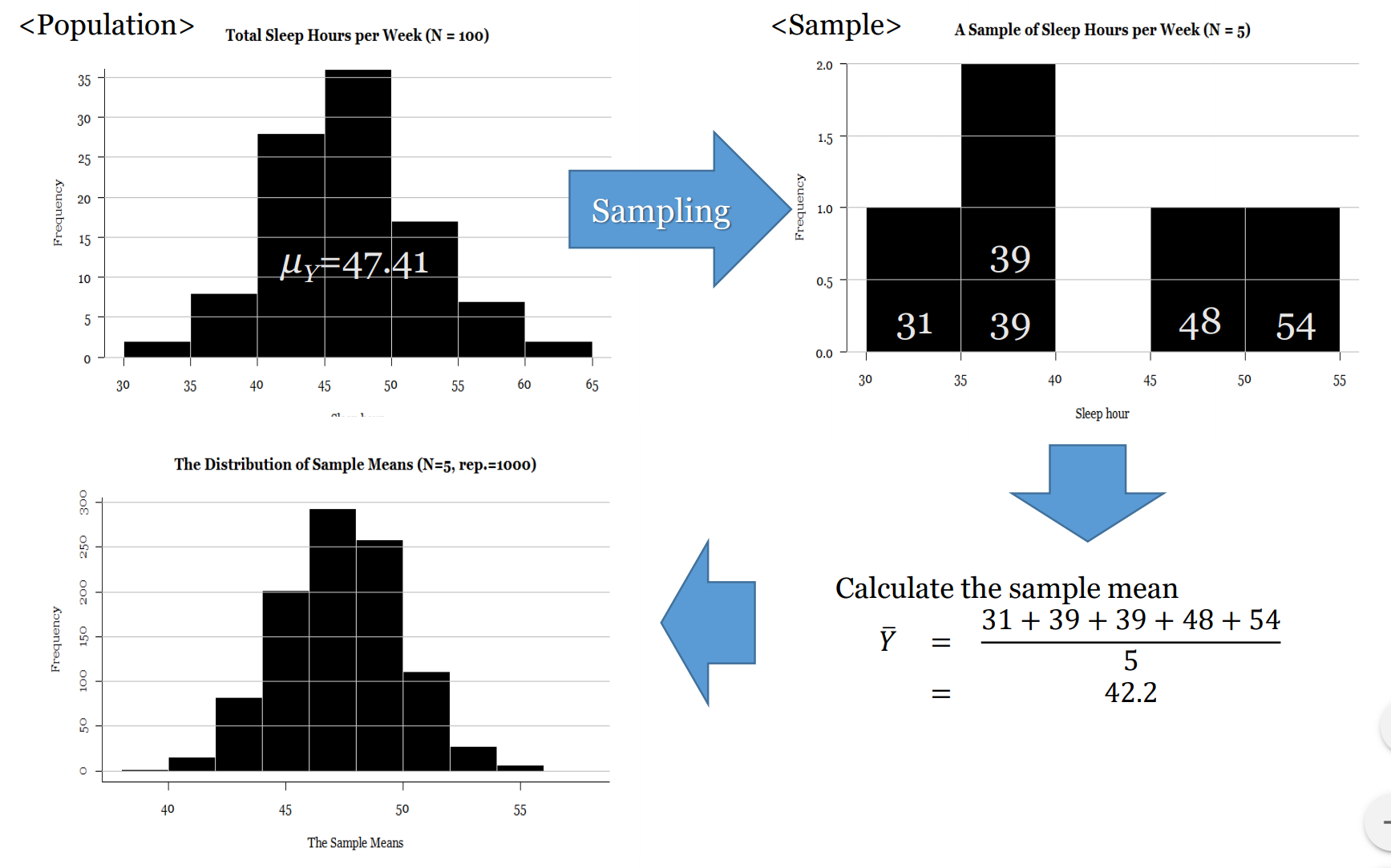
In descriptive statistics, we can actually see, touch, and/or count the group. We use descriptive statistics to describe entire populations we have measured - such as in a census - or to describe a sample (as the sample, not as a representative of the population).
This summary helps us turn a unwheldy set of numbers into one or two: a central tendence, and some indication of variable.
One example of using descriptive statistics is calculating the the median personal weekly personal income of people aged 15 years and over (which is $662) of the 23 million Australian’s who did the 2016 census. We get one number - $662/week - to represent 23,000,000 numbers.
1.2 Standard deviation/Interquartile range: Giving variation a number
We know from life, however, that the ‘most ordinary, normal, typical’ single example of anything is a gross simplication.
All sets have variety, and the second major type of descriptive statistic tries to capture this variety, and do it in just one number.
Standard deviation
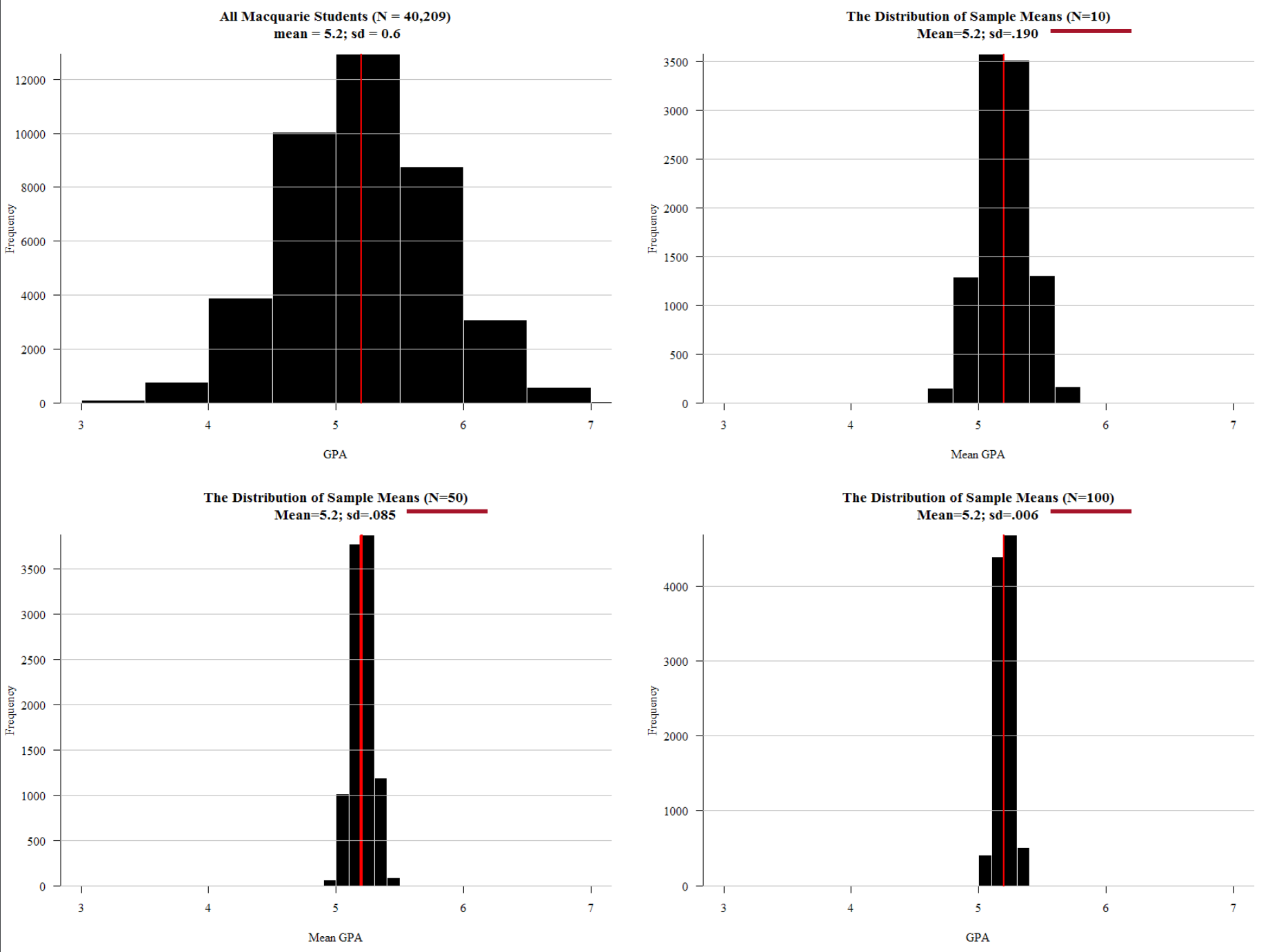
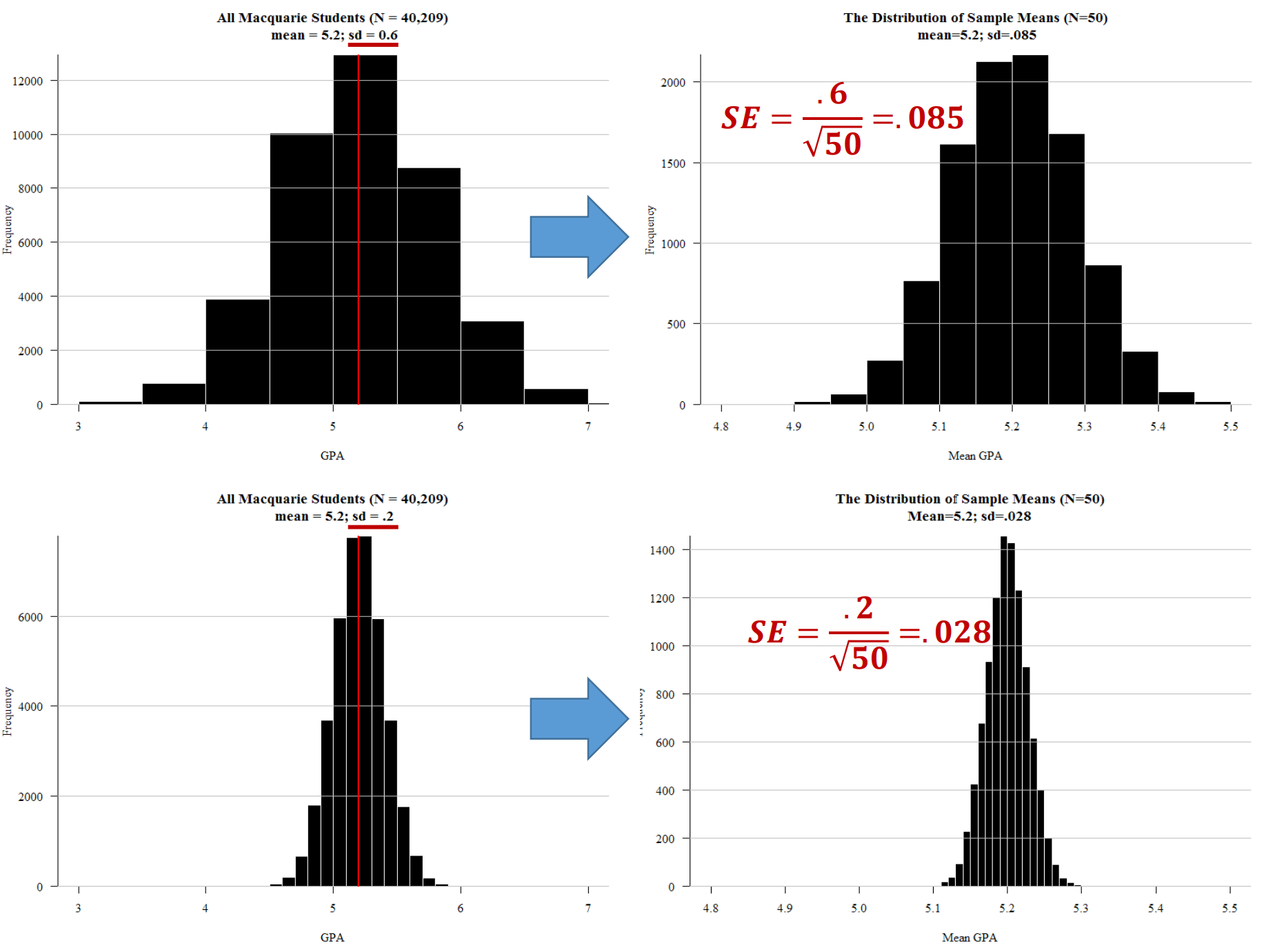
The most common measure of variety - or technically ‘variability’, ‘variation’, or ‘dispersion’ - in a set of numbers is probably the standard deviation.
Box 2 provides an explanation of standard deviation - as equation, and also in everyday language.
Intiutively - not strickly - you can think of standard deviation as the average amount - as an absolute value (so negative become positive, and positive stay positive) - that each person’s value for a variable ‘misses’ (deviates) from the mean of the variable.
If the standard deviation is close to zero, then virtually everyone in the dataset has the same value for the variable.
If the standard deviation is large, then you expect that - on average - any particular person you pick from the dataset is going to be quite distant from (greater or lesser than) the mean.
Interquartile range
While standard deviation is a good measure of variablity for normally distributed data, when we have skewed data (where there are a lot of numbers at one end of the range - like lots of low income people, and a few wealthy in an income distribution), then a better measure of variation is interquartile range, which simply means the range of the ‘middle 50%’ of a dataset. IQR = Q3 - Q1, where Q3 is the number on the boundary between the largest 25%, and the next 25%, and Q1, is the number on the boundary between the smallest 25% and the next 25%.
Box 2: Standard Deviation: As an equation and in everyday language
|
|
\(\begin{aligned} \text{Standard Deviation of variable x} = &\sqrt{\frac{\sum_{i=1}^n (x_i - \bar x)^2}{N}}\\ \\ \text{Where:} \\ x_i = &\text{value of x for each individual i} \\ \bar x = &\text{ mean of x} \\ N,n = &\text{ number of observations} \\ \sum_{i=1}^n = &\text{sum for all observations from 1 to n} \\ \end{aligned}\)
While this equation looks scary to many people, I think the best way to break it down - conceptually, and by analogy, not strict mathematically - is to think about this as having just three main parts:
- Variation from mean: First, it basically asks how much, each value of a variable (e.g. the age of each particular student in a class) varies from the mean for the whole set (e.g. the average age of the class). This is represented in the equation as: \[(x_i - \bar x)\]
- Averaged over all individuals: Second, it takes the average (mean) of this across all observations in the dataset (e.g. all students in the class). This is represented by the sum of (the funny E) divided by N: \[\frac{\sum_{i=1}^n \text{variation from mean} }{N}\]
- Punishing (counting) big variations more than small ones: Third, it actually squares the deviation from the mean - which has the effect of ‘punishing’ (i.e. inflating or more heavily weighting) larger deviations from the mean more. It then takes the square root of the whole thing, basically to counter act the effect of the squaring, and make it all measured in the same ‘units’ as the mean.
BUT, the take away from all this is: the standard deviation is - more or less - the average amount all values of a variable vary from the mean.
For example, you have two classes of 100 students each, and the average age (mean) of each class is 22, but the standard deviation of the first class is zero, and standard deviation of the second class is one.
Based on this standard deviation, you would know that - roughly and on average - if you picked any, say, six students from each class:
- the six students from the class with zero standard deviation would all be aged 22 (i.e. ages 22, 22, 22, 22, 22, 22), while
- the six students from class with one year standard deviation, would be comprised of students who - on average - deviate from the mean age by one year (e.g. ages 20, 21, 22, 22, 23, 24).
Notice that both groups have the same mean (22), but the second class is much more ‘dispersed’ and ‘varied’: the higher the standard deviation, the more ‘spread out’ the ages in the class are.
|
1.3 Minimum/Maximum: The bounds of our data
Another important set of descriptive statistics of any variable are the minimum and maximum values.
In the world of practical statistics, these numbers are very important because they give a sense of the absolute limits of the values of a dataset.
There are two main reasons you want to know this:
- Identify errors: Sometimes you make mistakes (or other make mistakes), and the minimum and maximum are often very easy ways to spot this. For example, if the minimum and maximum ages of a sample of adults is 17 and 999, you know that you have problems with your data at both ends. 17 means you have a person who could not consent to do the study, and 999 probably means that you have a missing value, and have not recoded it so the computer/statistical package knows it is missing (and not just a really big number).
- Identify skewness: It gives you another quick feel for the data. If the distribution is very skewed (e.g. income), then the minimum and maximum will look very different to the minimum and maximum for a classic normal distribution (e.g. height). Apparently if the average wealth was rescaled so it was equal to the average height, then the richest person would be more than 100km tall.
1.4 Percentile: For categories
Another type of descriptive statistic is the percentile. For example, the percentage of people who do not speak english at home, or the percentage of people who own dogs.
Percentiles are particularly useful for summarising categorical (nominal) data, as means, standard deviations, minimums, and maximums don’t tend to make sense.
1.5 N (number of non-missing cases): Did people actually answer this question?
The final important descriptive statistic we will cover is ‘N’ or ‘n’. This is the number of valid cases in a dataset, or the number of valid cases for a variable.
This number tells you how many people actually answered this question.
This is useful for spotting variables that have large numbers of missing data, which would skew the data, or, again, some sort of data entry problem (such as coding as missing, people who didn’t answer a question, but who can be assumed to be a zero or 1, e.g. “How religious are you?” may not be asked to people without a religion. However, we know that that number is not really missing, it is just very low. How religious are people with out religion? It is pretty safe to assume that they are not very religious!)