Reading‘Chapter 19: Logistic Regression’ in Andy Field, 2017. Discovering Statistics Using IBM SPSS Statistics. Sage. |
SummaryWe generally use logistic regressions when we have
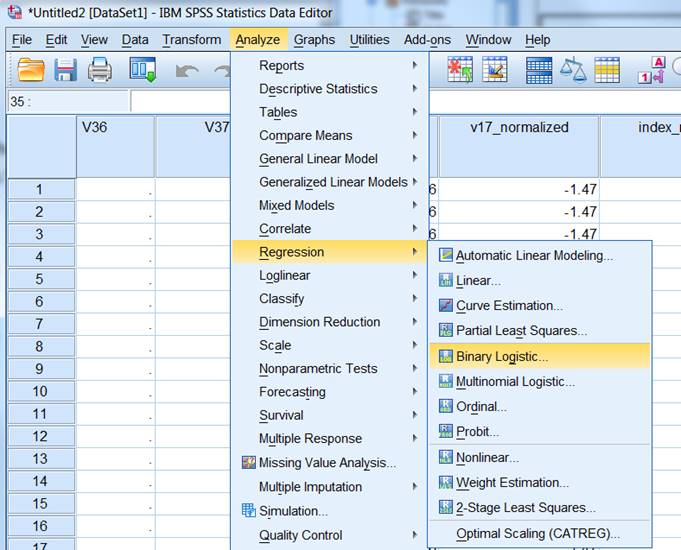
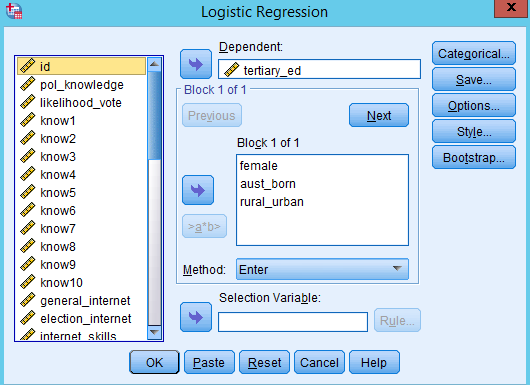
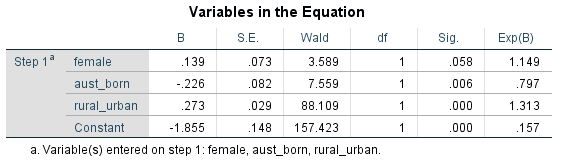
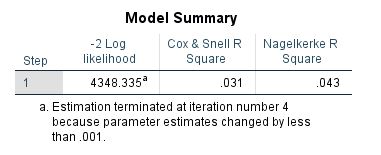
The process of running a regression in SPSS is basically the same as for linear regressions, with options for forced entry, hierarchical, and stepwise methods. When you read your results from a regression, you read the same two columns as in a linear regression (B and sig.). Significance (sig.) is read the same as for a linear regression. Because of the binary nature of the dependent variable in a logistic regression, the B is not so straightforward to interpret. B is basically a number which represents the impact of the independent variable on the probably of the dependent variable being 1. For this course, we are only going to interpret the significance, and direction (positive or negative) of B. We won’t interpret the magnitude. So for significant (< 0.05) B coefficients we say that independent variables with positive B (greater than 0) increase the likelihood of the dependent variable being 1 (and the reverse for negative B values). We can also view the various different R-square values for the model, which is approximately the same meaning as that for a linear regression. |