(b) Heirarchical entry of independent variables
Select Analyze > Regression > Linear
Select the dependent variable and put it in the top box
When you run HEIRARCHICAL models, you need to divide your independent variables into groups.
Select the FIRST SET of independent variables and put these in the ‘Independent(s)’ box
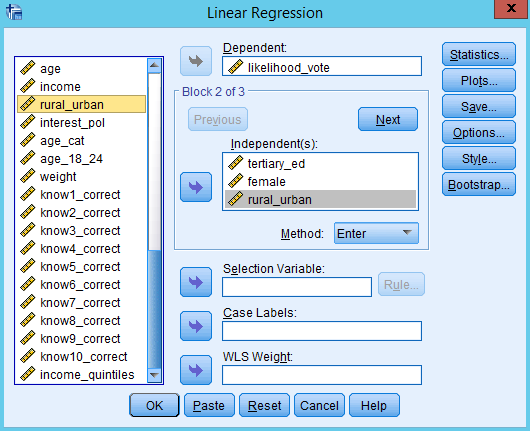
Press the ‘Next’ button. The independent variables box will clear.
Select the SECOND SET of independent variables and put these in the ‘Independent(s)’ box
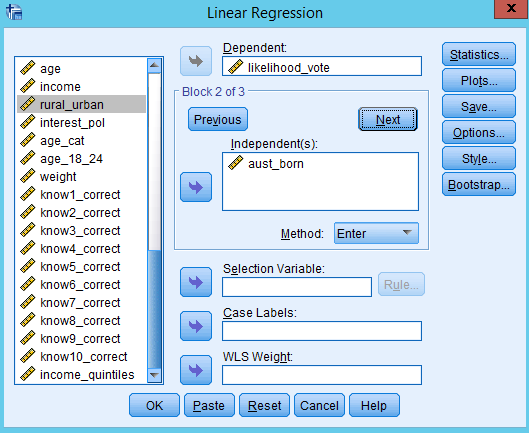
Press the ‘Next’ button. The independent variables box will clear.
Select the THIRD SET of independent variables and put these in the ‘Independent(s)’ box
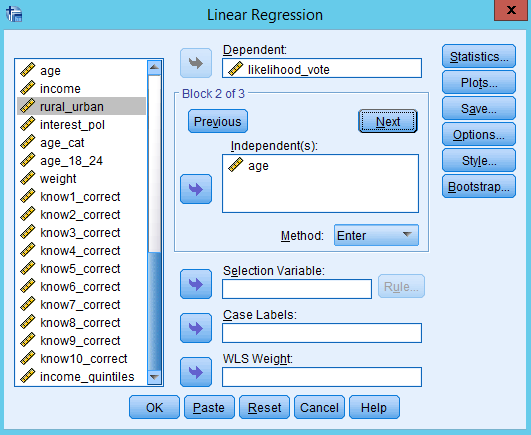
Press OK. The regression will run and the output screen will appear
How do you interpret a hierarchical linear regression?
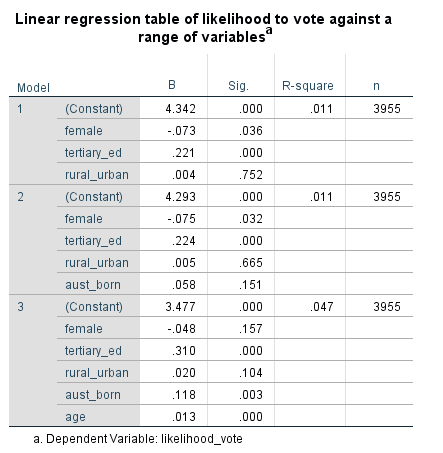
The simplest way to think about it is that each of Model 1, Model 2, and Model 3 are completely separate FORCED ENTRY models.
The coefficients for each variable in the three models are interpreted as ‘controlling for all the other variables in the model’. The difference with the later models (like Model 3) is that there are more controls (and more variables with coefficients).
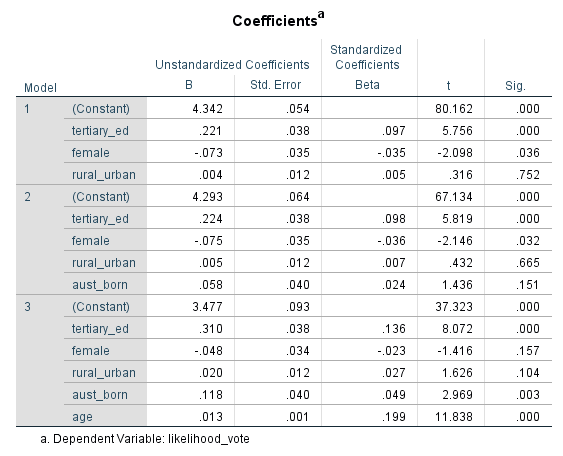
So how would we interpret this set of models?
Look in the ‘Sig.’ column for the p-values
If the p-value < 0.05 then the independent variable has a significant impact on the dependent variable
For the significant variables, we then read the B values (coefficients), which are the effect of a one unit increase of the independent variable on the dependent variable.
In this case the dependent variable is a scale from 1 to 5 with a higher number representing a lower likelihood to vote if voting was not compulsory.
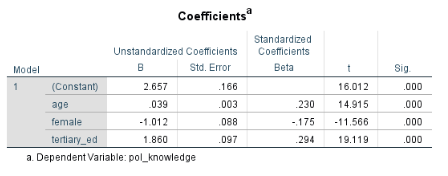
Let’s look at the transition of one variable - female - over the three models. Female is a binary variable with 0 meaning male and 1 meaning female.
In models 1 and 2, female is statistically significant (Sig. column p, 0.036 and 0.032 respectively).
In model 3, female becomes statistically insignificant (p = 0.157). Why? Because we added the variable age. When we control for age, gender (the variable called female) is no longer statistically relevant.
The fact that female loses significance when we add age suggests that the variables are related. A possible interpretation is this:
‘Women are more likely to vote (if voting was not compulsory) than men, but the reason this dataset shows this is that the male sample group is skewed towards a higher age than the female group (you can see this by doing a paired t test of age by gender or by comparing the historgram of age by gender). As people get older, they are less likely to vote (if voting is not compulsory). When controlling for the age of the respondents, gender is no longer statistically relevant. So women are more likely to vote but only because they are younger (in this sample).’
(c) Stepwise regression
WARNING: YOU SHOULD PROBABLY NOT BE RUNNING A STEPWISE REGRESSION
WHY? BECAUSE THEY ARE A-THEORETICAL, AND SO PRONE TO MASSIVE CONCEPTUAL FLAWS.
Let me show you through an example:
Select Analyze > Regression > Linear
Select the dependent variable and put it in the top box
When you run STEPWISE models, you tend to put a lot of variables into the model. You don’t generally have multiple blocks.
Select the independent variables and put these in the ‘Independent(s)’ box
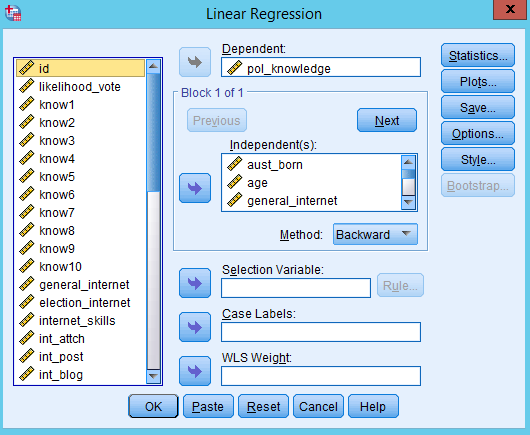
Under the independent variables, there is the label ‘Method’. Select ‘Backward’ from the dropdown menu.
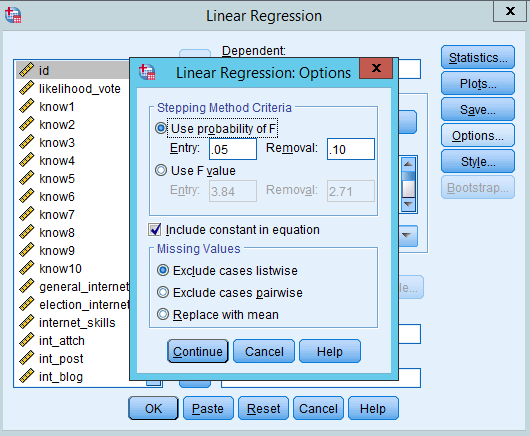
Click on ‘Options’.
This will reveal the options for ‘Stepping’. Because we are doing ‘Backwards selection’, you can just look at the ‘Removal’ box. Variables with Significance (p-value) greater than 0.10 will be removed from the model, one at a time. If you want you can adjust this up or down.
Press ‘Continue’. Then press OK and run the model
- How do you interpret stepwise linear regression?
First you need to wade through the huge mass of output.
The way a stepwise backwards selection regression works is that SPSS estimates a complete model with all the variables, and then if any variables have a significance of greater than 0.10, then it removes the one with the highest p-value (i.e. the least significant variable is removed). It then re-estimates the model, and repeats this process until only variables with p-values < 0.10 are left.
So generally we interpret a STEPWISE model by just interpreting the LAST model as a FORCED ENTRY model.
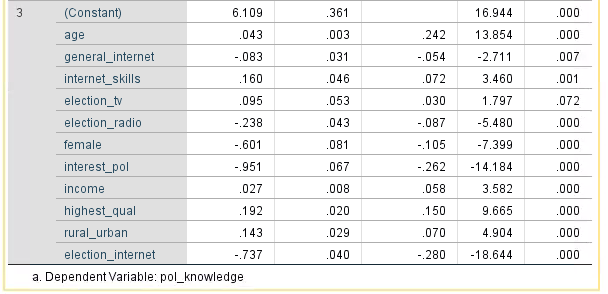
Here is the last model for our example. Notice the 3 next to the word (Constant). This is the model numbers, and this means that the method has dropped out 2 variables before getting to the final model. Dependending on how many variables you put in and their statistical relevance you could go through dozens of models.
So how would we interpret this set of models?
Look in the ‘Sig.’ column for the p-values
If the p-value < 0.05 then the independent variable has a significant impact on the dependent variable
Almost all the variables are significant at p < 0.05 level. But does this mean that we should SAY that these variables are a significant CAUSE of respondents’ political knowledge? What about the variables that have been excluded?
The Australian born variable was excluded in the first model because it had a p value over 0.10. But as we saw in the hierarchical model we did previously, the Australian born variable is interacting with other predictor variables. By running the hierarchical linear regression we were able to isolate that relationship, however in this stepwise regression method we are not able to to this.
THIS IS THE PROBLEM WITH STEPWISE MODELS: THEY DON’T DO THE THINKING FOR YOU, AND IF YOU GIVE IT SILLY MODELS, IT WILL STILL RUN THEM.